Authors: Yiming Ma, Victor Sanchez, Tanaya Guha
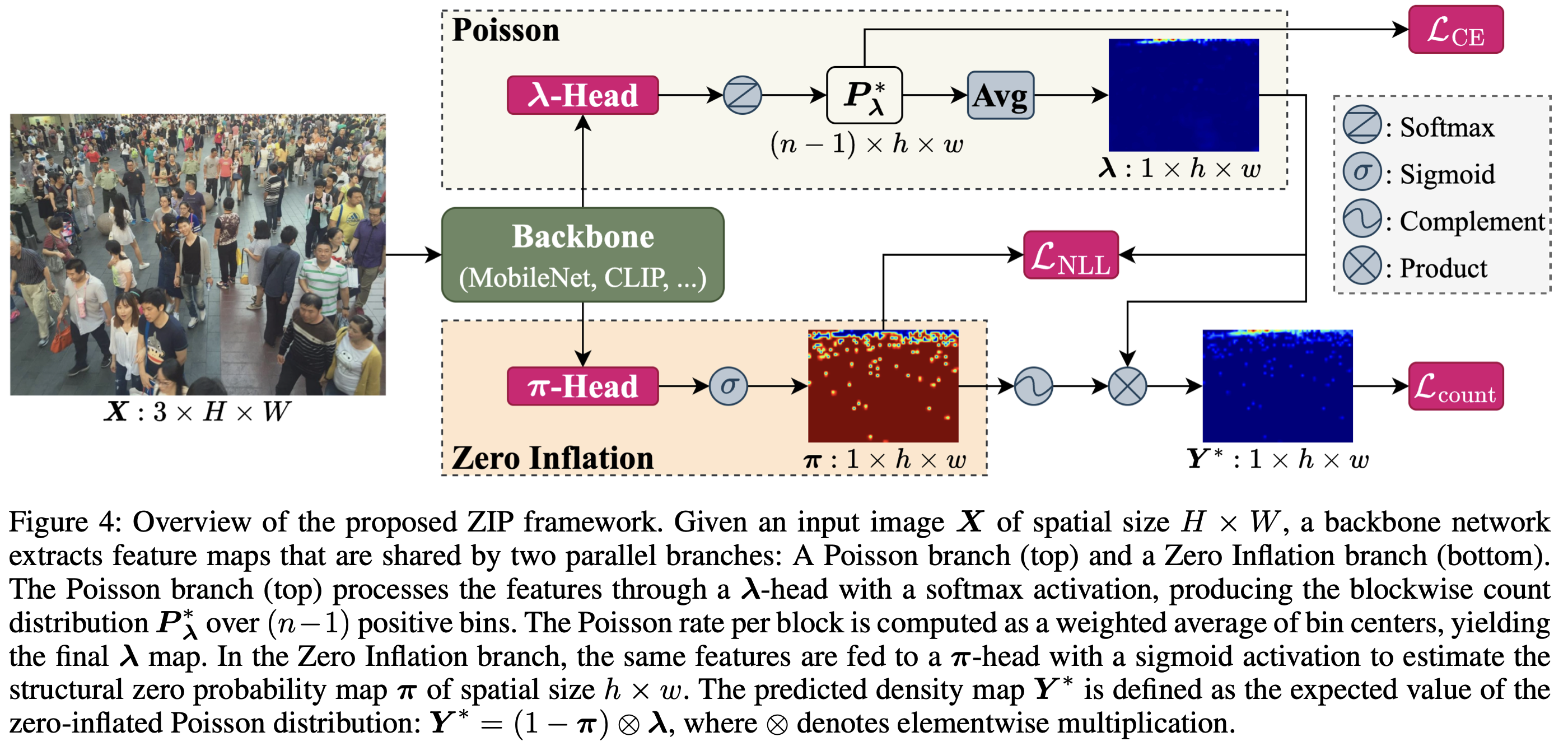
Most crowd counting methods directly regress blockwise density maps using Mean Squared Error (MSE) losses. This practice has two key limitations: (1) it fails to account for the extreme spatial sparsity of annotations - over 95% of 8x8 blocks are empty across standard benchmarks, so supervision signals in informative regions are diluted by the predominant zeros; (2) MSE corresponds to a Gaussian error model that poorly matches discrete, non-negative count data. To address these issues, we introduce ZIP, a scalable crowd counting framework that models blockwise counts with a Zero-Inflated Poisson likelihood: a zero-inflation term learns the probability a block is structurally empty (handling excess zeros), while the Poisson component captures expected counts when people are present (respecting discreteness). We provide a generalization analysis showing a tighter risk bound for ZIP than MSE-based losses and DMCount provided that the training resolution is moderately large. To assess the scalability of ZIP, we instantiate it on backbones spanning over 100x in parameters/compute. Experiments on ShanghaiTech A & B, UCF-QNRF, and NWPU-Crowd demonstrate that ZIP consistently surpasses state-of-the-art methods across all model scales.

 [80, center]
[80, center]