FusionCount: Efficient Crowd Counting via Multiscale Feature Fusion
Abstract
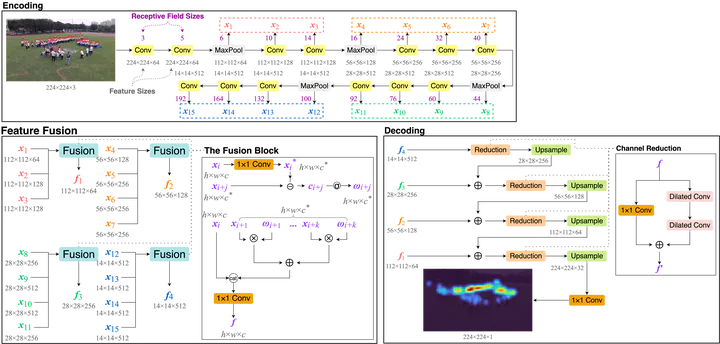
State-of-the-art crowd counting models follow an encoder-decoder approach. Images are first processed by the encoder to extract features. Then, to account for perspective distortion, the highest-level feature map is fed to extra components to extract multiscale features, which are the input to the decoder to generate crowd densities. However, in these methods, features extracted at earlier stages during encoding are underutilised, and the multiscale modules can only capture a limited range of receptive fields, albeit with considerable computational cost. This paper proposes a novel crowd counting architecture (FusionCount), which exploits the adaptive fusion of a large majority of encoded features instead of relying on additional extraction components to obtain multiscale features. Thus, it can cover a more extensive scope of receptive field sizes and lower the computational cost. We also introduce a new channel reduction block, which can extract saliency information during decoding and further enhance the model’s performance. Experiments on two benchmark databases demonstrate that our model achieves state-of-the-art results with reduced computational complexity.
Type
Publication
In IEEE International Conference on Image Processing